Monaural Speech Enhancement through Deep Wave-U-Net: In this paper we present an end-to-end approach to reduce noise from speech signals. This background context is detrimental to several downstream applications, including automatic speech recognition (ASR), word spotting and sentiment analysis. In the limit, those systems can produce high error rates and become unusable. The input of the network is an audio waveform, with 16kHz of sample rate, corrupted by an additive noise. Our proposed system aims to produce a signal with clean speech content.
The method is based on the Wave-U-Net architecture with some adaptations to our problem. An enhancement to that original model consists of a weight initialization through an autoencoder before training for the main task, which leads to a more efficient use of training time. Through quantitative metrics, we show that our method is prefered over the classical Wiener filtering and that also our system leads to better results on speech-to-text tasks.
tl;dr: You can check out the results here before read how the network works. If you enjoy the results, come back!
tl;dr 2: A full version of the paper can be found here. It is more detailed and you can find more information on how the work was conducted.
Introduction
Background content extraction from speech signals is the primary task of speech denoising, being useful for human understanding and automatic speech recognition (ASR) problems (e.g. speech-to-text). In particular, high word error rates (WER) have shown to deteriorate performance of sentiment analysis.
In contrast, work has also been conducted to enhance performance in the audio domain. We note that this clean voice extraction on single-channel records is a highly under-determined problem due to the complexity of audio nature itself.
Recent approaches to this problem relies on spectral information and other pre-processing techniques on their pipeline. One of the biggest issues in this approach is the arise of artifacts on the enhanced signal when performing inverse short-time Fourier transform. This problem can be relieved by using a directly pipeline on the raw waveform.
In this work, we propose a end-to-end deep learning approach using Fully-Convolutional Neural Networks to address the problem of denoising speech audio. That is, we attempt to increase the speech signal to make it more palatable for ASR and sentiment analysis systems. In practical terms, we are further developing an architecture based on the U-Net model for one-dimensional time-domain, as proposed by the Wave-U-Net paper.
U-Net
The typical use of a convolutional network it is on classification problems where the output is a single class label to identify that image. Semantic segmentation is a popular research field, especially on biomedical image processing, where the idea is to understand an image at pixel level, i.e., a class label could be assigned to each pixel.
The U-Net model was proposed by Ronneberger et al to solve the segmentation problem of neuronal structures in EM (electron microscope) stacks and won the ISBI challenge.
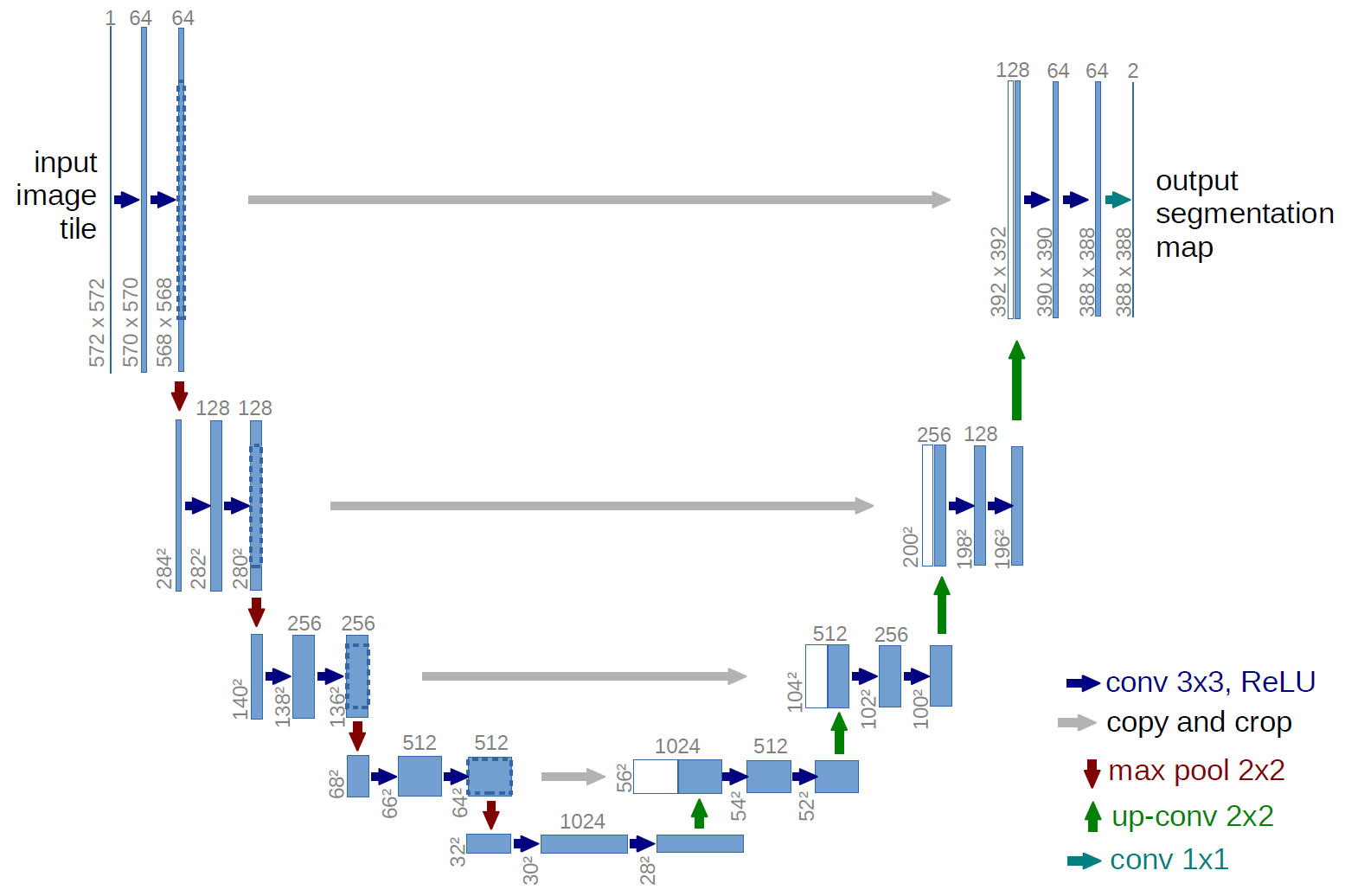
In the figure above we can see the architecture of the U-Net. It is a fully convolutional neural network, with a contracting path (left side), a bottleneck layer and an expansive path (right side). The left path follows a typical architecture of a CNN, where we repeatedly apply two convolutions without padding and followed by a non-linear activation function (ReLU) and a maxpooling operation for downsampling. While we downsample the space in factor of 2, we double the number of feature channels in the network.
Wave-U-Net and our model
The Wave-U-Net combines elements from the U-Net architecture, by using the raw-waveform and one-dimensional convolutions, with some of the architectures discussed before. The network consists of a contracting path (the left side) and an expansive path (right side) similar with the U-Net, but using one-dimensional convolutions as our basic block. A schema of the network can be found on figure below.
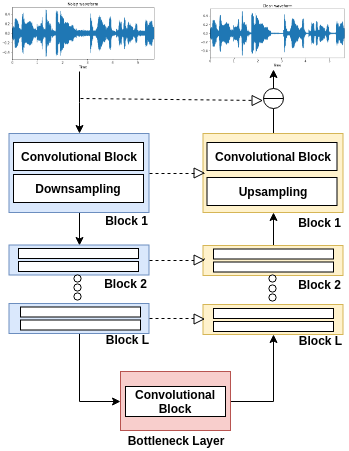
Each layer, or block, on the diagram has a convolutional block followed by a downsample or preceded by an upsample operation. The convolutional block is constituted by an one-dimensional convolution and a non-linear activation function. All the layers, except for the last in expansive path, has a LeakyReLU activation. The last layer (block 1 on expansive path) has a Tanh activation. The downsample module is a decimate operation where we halve the dimension of the feature map. In the upsample module we tested some combinations as linear interpolation and transposed convolutions.
We have tested multiple architectures and hyperparameters based on the Wave-U-Net model. There are four major differences between our model and the original Wave-U-Net:
-
Upsampling method: Stoller has proposed a learning interpolation layer, where the intermediate value could be learned. A simple linear interpolation had a good performance on our task and was chosen as the main upsampling operation. Transposed convolutions were also tested.
-
Loss function: Several papers have proposed different loss functions for this problem, most of it based on a regression loss. We tested the efficiency of MAE over MSE to build our network.
-
Weight initialization: In this paper we initialy train the proposed method as an autoencoder before training the network for the main task of speech denoising. The idea is to use a reserved part of the dataset only with clean speechs to extract features useful for voice segmentation and speed up the training.
-
Reflection-padding: To avoid the creation of artifacts on border regions, introduced by zero-padding, we use a reflection-padding layer. Instead of fill with zero the borders, we replicate samples at border regions to fill the required space.
Experiments
We constructed the dataset based on the mixture of the LibriSpeech (train-clean-100), for clean voice, and the UrbanSound8K for noises. The noises are inserted through an additive process with a controlled level of disturb by changing the amplitude and energy of the noise signal. The signal-to-noise ratio (SNR) between the clean voice and the mixture on training set is in the range of 5db and 15dB, uniformly distributed. The data is divided into small windows of ≈4.1s (2^16 samples).
We also used the test-clean subset of LibriSpeech to test the system effiency on ASR models. This subset is not divided into small windows, we use the data with full-lenght. The noise inserted on this subset is the same that we used on the test set of the Wave-U-Net test noises, but in multiple SNR intervals.
For this paper we will compare a set of three models, denoted by M = {M1, M2, M3}. M1 is a naive implementation of the model proposed on the Wave-U-Net paper but with a simple linear interpolation on the upsampling block. M2 is very similar with the first model but we are going to use transposed convolutions for upsampling operations. And for the last step, for the model M3, we select the architecture with best performance between M1 and M2 and then we start to train the network as an autoencoder for weight initialization step to after that training for the main task of noise removal.
For all architectures we used similar structures. The networks have a depth of 5 blocks on both paths (L = 5). The convolutions on the contracting path have a kernel of size 15 and in the expansive path a kernel size of 5. Also, to keep the feature map on the same size after the convolutional block, we use a reflection-padding layer before convolutioning the input, with a window of size k // 2, where k is the kernel size. The number of filters in each layers was designed as in the Wave-U-Net paper but with 8 additional filters per layer, as the following formula: F = 24i + 8, for i ∈ {1, …, L}.
A last additional step was taken in order to show a pratical application of the winning model. Using the separate test set we evaluate the performance of the ASR system Deep Speech, a speech-to-text model proposed by Baidu Research and implemented in tensorflow by Mozilla.
The Deep Speech is an end-to-end deep learning system on top of large RNNs and language models. Compared to other systems, Deep Speech does not need domain experts to invest a great effort on input features or acoustic models. One of the most notable features of Deep Speech is the capability to handle challenging noisy environments better than most of the other ASR solutions available.
In this experiment our hypothesis relies on the fact that additive noises can hurt ASR performance, even on robust systems as Deep Speech. The idea is to apply the winning model and compare the word error rate (WER) of the extracted sentences of the original audio, the corrupted audio and the enhanced audio.
Results
Under the conditions described above, we trained our three models over 25 epochs and the result on test set can be found on table bellow. The measurement is calculated between the enhanced speech and the clean target. Also, the SNR and loss curves for validation set can be found on figure bellow.
| Baseline | Wiener | M1 | M2 | M3 |
|---|---|---|---|---|
| 10.1 | 12.9 | 14.5 | 14.1 | 15 |
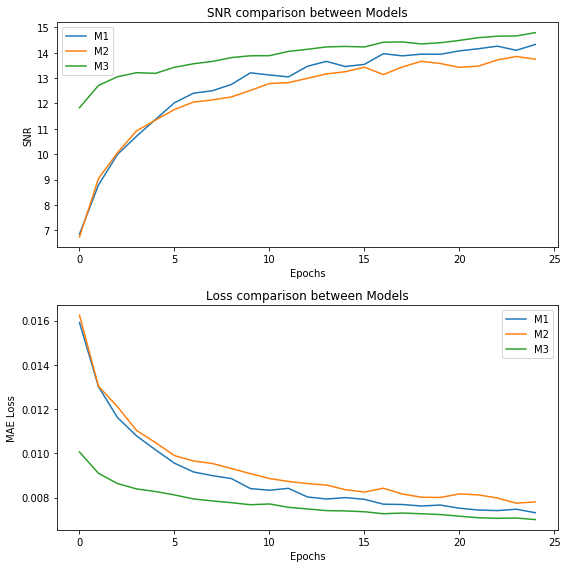
From table above we can see that all of our methods are preferred over Wiener filter. Model M3 had the best performance on the SNR metric. Being initialized with an autoencoder gave the model a boosting in both performance at the start point and allowed the model to learn for more time.
As M3 was the best model on this task, we trained again the model for 100 epochs. The SNR reached on this task was of 15.8.
To evaluate a pratical usage of our model, we tested an ASR model to transcribe noisy and processed audios. The table bellow shows the results of our experiment, meaning that the usage of this network as an preprocessing step for speech-to-text algorithm has the potential to reduce errors. The word error rate of the ground truth (clean test set before insert noises) is 9.63%.
| SNR Interval (db) | Noisy Signal (WER) | Processed Signal (WER) |
|---|---|---|
| [0, 10] | 52.68% | 40.93%, |
| [5, 15] | 34.46% | 26.56% |
| [10, 20] | 21.77% | 18.49% |
To hear some of the results you can access the result here.